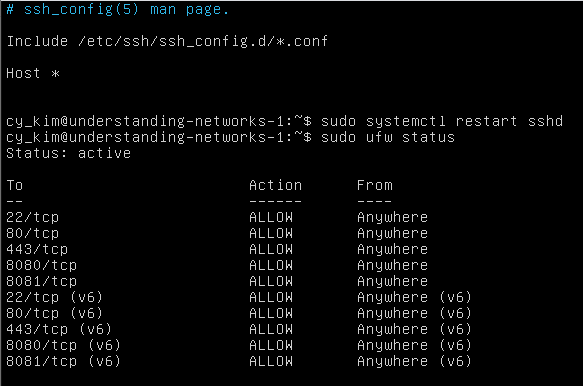
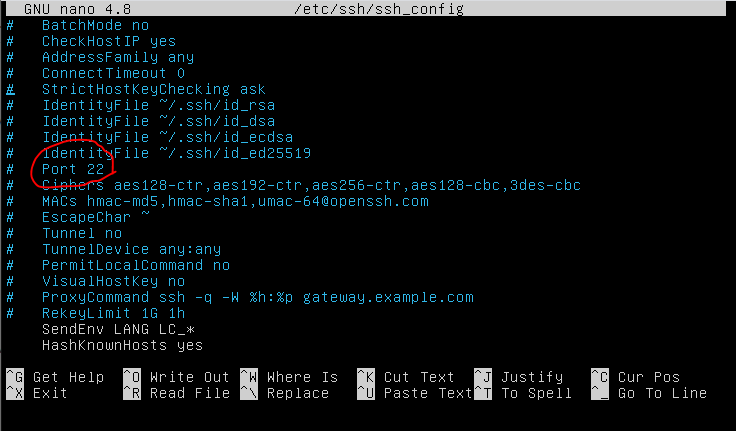
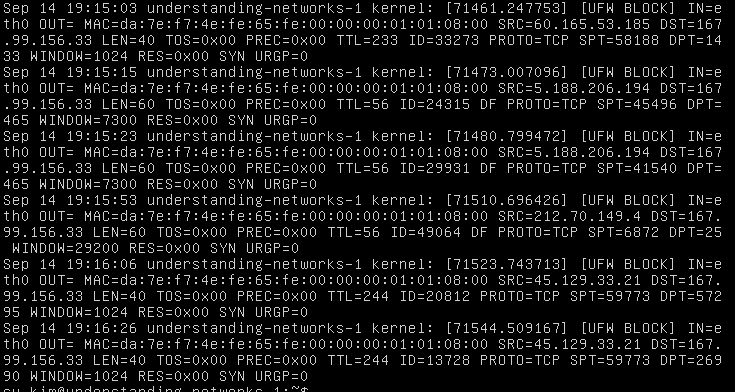
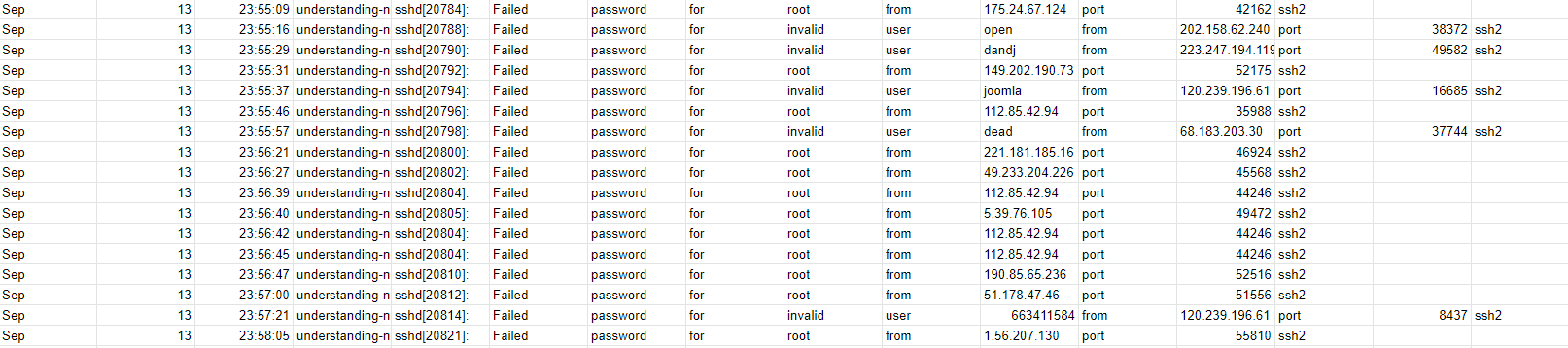
Here is the link to the github.
In collaboration with Yiting Liu and Name Atchareeya.
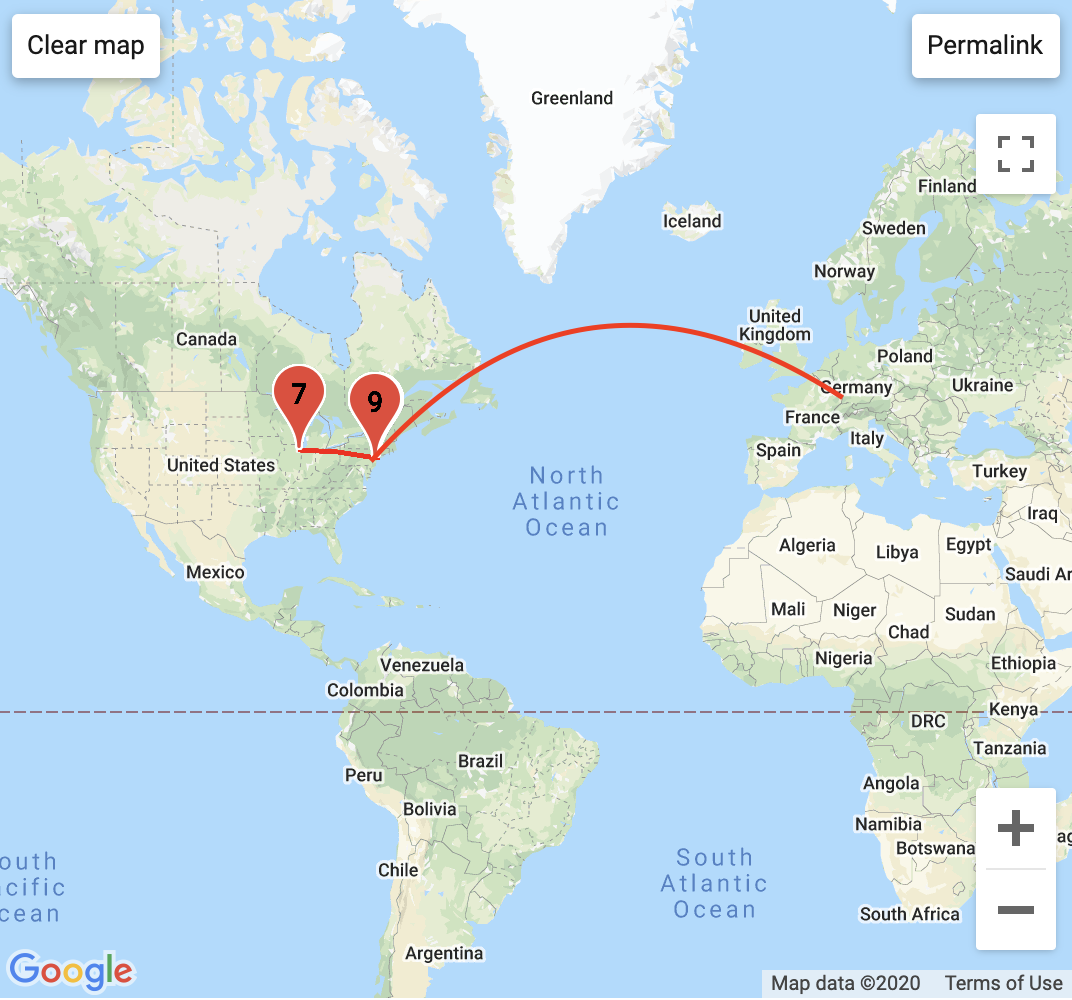
System Diagram created by Name
Two other ITP Weather Band members and I thought it would be a good opportunity to apply what we learned from this class to build the API that allows the transfer, access and storage of weather data between the sensors, databases and clients. Below is the systems digram that show the components involved and their relationship to one another. To begin, the weather station and the enviro-shield is located on Yeseul Song’s apartment fire escape in East Village, NYC, which is connected to an Arduino MRKR1010. The Arduino sends data from the sensors every minute to the mySQL database on the Digital Ocean VPS which can be accessed by a p5 client, an Arduino client or any web-client made possible by the API. This final project is what got me to finally understand what an API is and it’s not that I haven’t looked up the definition before but doing it in practice really cemented my understanding, especially as someone who does not come from a software background.
In terms of divvying up the project. Name took charge with the API and adapting the code from the previous iteration of the Weather Band API. Refer to the github or Name’s blog post or the github for a break down of the API. Yiting was in charge of the web client that would also be revised to be the public facing documentation page for the Weather Band. My role was to set up the mySQL database as well as help Yiting with fetching the data and displaying it properly in the webclient. It was in this role that I finally understood the importance of callback functions because Javascript is an asynchronous language and will progress to the next operation before a prior action is completed. This became an issue as we were trying to load the JSON file of data that we got as a response from the server and display it but the code would execute the draw() function before the file had been fully loaded.
Overall, this was a really great exercise to gain a comprehensive understanding of what goes into an IoT device that can store data which can be accessed by other devices. I can foresee my thesis project adapting this system in a different application.